Tác giả: TrongTran
Ngày: 22/10/2019
Tài liệu tham khảo: https://tel.archives-ouvertes.fr/tel-01053729/file/Distributed_clock_generator_for_synchronous_SoC_using_ADPLL_network.pdf
và các nguồn tư liệu từ internet,
Tham khảo một số hình ảnh waveform từ Wikipedia.
Hi, Lại là mình đây.
Hôm nay mình tiếp tục nói về các lỗi trong thiết kế mạch bất đồng bộ. Phần hôm nay tập trung vào tín hiệu data bất đồng bộ (không phải tín hiệu control nhé, tín hiệu control sẽ được nói trong bài tiếp theo).
Trường hợp 1
Đầu tiên và cơ bản nhất đó là lỗi không dùng mạch đồng bộ cho các tín hiệu bất đồng bộ.
Điều này sẽ gây ra hiện tượng bất ổn định hay còn gọi là metastabilities.

Trong hình trên, nếu tín hiệu w1 thay đổi (0->1 hoặc 1->0) trong khoảng từ hold time hoặc setup time của clock c2 thì lúc này hiện tượng metastabilities xảy ra.
Trạng thái metastabilities là trạng thái data không xác định được giá trị. Phải mất một khoảng thời gian để đạt trạng thái ổn định.

Thời gian để tín hiệu trở nên ổn định. Nghĩa là từ khi xảy ra metastabilities đến khi đạt trạng thái 0 hoặc 1 gọi là closure time (Có thể gọi là metastable phase).
Close sure time được định nghĩa như bên dưới:
Clock cycle ≧ Closure time + Tsetup + Tskew + Tjitter
↑ ↑ ↑
FF thứ nhất FF thứ hai clock properties
Như vậy MTBF sẽ phụ thuộc vào 3 yếu tố:
Với một MTBF cho trước và thời gian closure time cho trước ta có thể lựa chọn thư viện cho FF đầu tiên trong mạch 2 FF phù hợp để có được design mong muốn.
Thế nên chúng ta mới có khái niệm meta FF, đó là các flip flop có tuổi thọ cao , bền và có các thông số phù hợp với MTBF và closure time cho trước.
Nếu điều kiện trên không thoả, nghĩa là chúng ta không thể chọn được FF đầu tiên phù hợp với mục đích ban đầu đưa ra thì có 2 cách giải quyết:
Cái này thì mình chịu nè. Mình chưa biết đồng bộ khoá pha là gì. Chắc sẽ bổ sung sau.

Hoặc:




Vậy trong mạch đồng bộ, glitches có xuất hiện không. Câu trả lời là có. Tuy nhiên thời gian glitch tồn tại nhỏ và khi data truyền đến chu kì tiếp theo của clock (Cạnh lên clock tiếp theo) thì nó sẽ không capture được glitch để transfer. Ý mình là thời gian glitch kết thúc luôn sớm hơn thời gian bắt đầu một chu kì clock mới (data lúc này mới được capture). Còn nếu delay quá nhiều dẫn đến glitch ảnh hưởng đến cạnh clock lên tiếp theo thì cái này STA sẽ control.
Glitches trở nên sai trong mạch bất đồng bộ trường hợp khi glitch vừa lên lúc này đúng ngay khoảng thời gian từ setup time hoặc hold time của clock phía nhận. Và data được transfer đi không đúng như chúng ta mong muốn.
Trường hợp 3
Trường hợp một output từ khối A bạn muốn nối đến nhiều input của khối B. Bạn phân nhánh nó tại khối A và dùng nhiều mạch đồng bộ cho từng nhánh đó. Điều đó có thể dẫn đến sự khác nhau về giá trị giữa các nhánh đó.

Nguyên nhân là sau FF đầu , tín hiệu chuyển sang trạng thái metastabilities và lúc này FF 2 sẽ có thể bắt tín hiệu khác nhau là 0 hoặc 1. Dẫn đến tín hiệu ngõ ra có thể bị shift. Nghĩa là tín hiệu ngõ ra giữa out_2 và out_3 sẽ không giống nhau.
Ngày: 22/10/2019
Tài liệu tham khảo: https://tel.archives-ouvertes.fr/tel-01053729/file/Distributed_clock_generator_for_synchronous_SoC_using_ADPLL_network.pdf
và các nguồn tư liệu từ internet,
Tham khảo một số hình ảnh waveform từ Wikipedia.
Hi, Lại là mình đây.
Hôm nay mình tiếp tục nói về các lỗi trong thiết kế mạch bất đồng bộ. Phần hôm nay tập trung vào tín hiệu data bất đồng bộ (không phải tín hiệu control nhé, tín hiệu control sẽ được nói trong bài tiếp theo).
Trường hợp 1
Đầu tiên và cơ bản nhất đó là lỗi không dùng mạch đồng bộ cho các tín hiệu bất đồng bộ.
Điều này sẽ gây ra hiện tượng bất ổn định hay còn gọi là metastabilities.

Trong hình trên, nếu tín hiệu w1 thay đổi (0->1 hoặc 1->0) trong khoảng từ hold time hoặc setup time của clock c2 thì lúc này hiện tượng metastabilities xảy ra.
Trạng thái metastabilities là trạng thái data không xác định được giá trị. Phải mất một khoảng thời gian để đạt trạng thái ổn định.

(Ảnh nguồn : http://hardwarebee.com/metastability-in-fpgas/)
Trong hình bên trên chúng ta có thể thấy tín hiệu Din thay đổi ngay trong khoảng thời gian từ setup time đến hold time của clock clk2. Tuy nhiên tại đây Din không xác định giá trị là 0 hay 1 (Vì độ nghiên của cạnh data). Từ đó FF đầu tiên chạy với CLK2 không thể bắt chính xác giá trị từ Din và trạng thái bất ổn định xảy ra. Ta dùng 2 FF nhầm loại bỏ trạng thái này vì hầu như sau 1 chu kì xung clock CLK2, tín hiệu ngõ ra Ds đã ổn định và FF thứ hai chạy với clock CLK2 đã bắt đúng giá trị ổn định đó.
Trong hình bên trên chúng ta có thể thấy tín hiệu Din thay đổi ngay trong khoảng thời gian từ setup time đến hold time của clock clk2. Tuy nhiên tại đây Din không xác định giá trị là 0 hay 1 (Vì độ nghiên của cạnh data). Từ đó FF đầu tiên chạy với CLK2 không thể bắt chính xác giá trị từ Din và trạng thái bất ổn định xảy ra. Ta dùng 2 FF nhầm loại bỏ trạng thái này vì hầu như sau 1 chu kì xung clock CLK2, tín hiệu ngõ ra Ds đã ổn định và FF thứ hai chạy với clock CLK2 đã bắt đúng giá trị ổn định đó.
Thời gian để tín hiệu trở nên ổn định. Nghĩa là từ khi xảy ra metastabilities đến khi đạt trạng thái 0 hoặc 1 gọi là closure time (Có thể gọi là metastable phase).
Close sure time được định nghĩa như bên dưới:
Clock cycle ≧ Closure time + Tsetup + Tskew + Tjitter
↑ ↑ ↑
FF thứ nhất FF thứ hai clock properties
Như vậy MTBF sẽ phụ thuộc vào 3 yếu tố:
- Tần số clock C1, C2.
- Đặc điểm thư viện flip flop.
- Closure time.
Thế nên chúng ta mới có khái niệm meta FF, đó là các flip flop có tuổi thọ cao , bền và có các thông số phù hợp với MTBF và closure time cho trước.
Nếu điều kiện trên không thoả, nghĩa là chúng ta không thể chọn được FF đầu tiên phù hợp với mục đích ban đầu đưa ra thì có 2 cách giải quyết:
- Tăng số tầng FF đến 3 FF hoặc 4 FF. Tuy nhiên, cách này sẽ làm tăng latency của hệ thống.
- Trường hợp nếu tăng latency không được chấp nhận thì còn một cách là sử dụng bộ đồng bộ hoá pha.
Cái này thì mình chịu nè. Mình chưa biết đồng bộ khoá pha là gì. Chắc sẽ bổ sung sau.
Một trường hợp khác cũng gây ra lỗi tương tự đó là fanout tín hiệu giữa 2 mạch 2FF như hình dưới:

Hoặc:

Tín hiệu metastabilities không nên đưa vào các mạch logic vì sẽ gây ra sai fucntion cũng như ảnh hưởng đến hệ thống.
Trường hợp 2
Lỗi thứ hai liên quan đến việc chèn các logic trước mạch async 2FF như hình bên dưới:
Lỗi thứ hai liên quan đến việc chèn các logic trước mạch async 2FF như hình bên dưới:

Việc này sẽ gây ra glitch. Nghĩa là giả sử có sự delay giữa hai wire w1 và w2 như trên hình (Nguyên nhân có thể do dây dẫn, do combinational logic, ...). Thì lúc này glitch sẽ xuất hiện tại w3.
Các bạn tham khảo glitch như hình dưới:
Mình lấy ví dụ combinational logic là cổng AND.

Lúc này Glitch sẽ xuất hiện như sau:

Dữ liệu đúng phải là:
Tại xung clock lên X, tín hiệu w1 sẽ từ 1->0 và w2 sẽ từ 0->1. Lúc này kết qua w3 phải là = 0 vì 1 & 0 = 0. Tuy nhiên vì w1 vì một lí do nào đó bị delay như hình trên lúc này w3 sẽ có 1 khoảng 1&1 = 1. Hình trên clock C2 không bắt được glitch nên đầu ra không sao. Tuy nhiên, trường hợp glitch bị ngay trong khoảng thời gian từ setup time đến hold time của clock C2 thì glitch sẽ được capture và đầu ra sẽ bằng 1 trong 1 chu kì chứ không phải là 0 như kết quả ban đầu.
Vậy trong mạch đồng bộ, glitches có xuất hiện không. Câu trả lời là có. Tuy nhiên thời gian glitch tồn tại nhỏ và khi data truyền đến chu kì tiếp theo của clock (Cạnh lên clock tiếp theo) thì nó sẽ không capture được glitch để transfer. Ý mình là thời gian glitch kết thúc luôn sớm hơn thời gian bắt đầu một chu kì clock mới (data lúc này mới được capture). Còn nếu delay quá nhiều dẫn đến glitch ảnh hưởng đến cạnh clock lên tiếp theo thì cái này STA sẽ control.
Glitches trở nên sai trong mạch bất đồng bộ trường hợp khi glitch vừa lên lúc này đúng ngay khoảng thời gian từ setup time hoặc hold time của clock phía nhận. Và data được transfer đi không đúng như chúng ta mong muốn.
Trường hợp 3
Trường hợp một output từ khối A bạn muốn nối đến nhiều input của khối B. Bạn phân nhánh nó tại khối A và dùng nhiều mạch đồng bộ cho từng nhánh đó. Điều đó có thể dẫn đến sự khác nhau về giá trị giữa các nhánh đó.

Nguyên nhân là sau FF đầu , tín hiệu chuyển sang trạng thái metastabilities và lúc này FF 2 sẽ có thể bắt tín hiệu khác nhau là 0 hoặc 1. Dẫn đến tín hiệu ngõ ra có thể bị shift. Nghĩa là tín hiệu ngõ ra giữa out_2 và out_3 sẽ không giống nhau.
Hình dưới biểu thị data tại ngõ ra đã bị shift và không giống nhau.
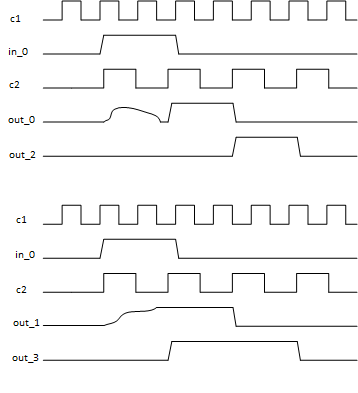
Hãy dùng mạch 2 FF để đồng bộ tín hiệu output trước sau đó hãy phân nhánh nó vào từng input hợp lí. Điều này giúp giảm gate size của chip vì ta không cần đồng bộ cho từng nhánh mà chỉ đồng bộ 1 tín hiệu rồi phân nhánh nó sau khi đã đồng bộ.
Trường hợp 4
Phân nhánh data sau FF thứ nhất trong 2 FF. lúc này STA check không thể kiểm tra timing cho path này và sự delay khác nhau của các line này có thể gây ra việc shift data trong output của FF thứ 2.

Hiện tượng trong trường hợp này khá giống như trường hợp 3 bên trên.
Trường hợp 5
Data có thể bị lost nếu như độ rộng của xung data nhỏ hơn 1,5 lần chu kì clock nhận.
Mình nghĩ cái này khá là cơ bản và bạn nào cũng có thể biết. Có nhiều tài liệu nói về vấn đề này. Một số tài liệu ghi là xung data phải lớn hơn 2 lần. Tuy nhiên mình nghĩ 1,5 lần là đủ rồi.
Bạn thử nghĩ nếu xung data quá nhỏ. Lỗi hay gặp là transfer từ clock nhanh sang clock chậm. Data toggle sau khi cạnh clock lên và trước cạnh clock lên tiếp theo của clock C2 thì FF thứ 2 sẽ không capture được. Đây là một lỗi tưởng đơn giản nhưng rất nguy hiểm đấy nhé.
Hãy cẩn trọng với confirmation cho các path như thế này.
Trường hợp 6
Có lẽ đây là trường hợp cuối cùng trong phạm vi hiểu biết của mình về lỗi trong mạch đồng bộ tín hiệu data.

Trong 1 bus nhiều tín hiệu. Chúng ta không được sử dụng mạch đồng bộ cho từng tín hiệu riêng lẽ vì nhu vậy data trong bus sẽ bị thay đổi.
Với một bus chúng ta sẽ có mạch đồng bộ riêng để nhầm tránh sự sai biệt này.
Hôm nay viết dài rồi. Chắc bữa khác mình bổ sung hi vọng nó giúp bạn có cái nhìn tốt hơn về vấn đề đồng bộ mạch async. Nếu có gì sai sót vui lòng gửi comment hoặc gửi mail góp ý cho mình : Trongk10@gmail.com

Hãy dùng mạch 2 FF để đồng bộ tín hiệu output trước sau đó hãy phân nhánh nó vào từng input hợp lí. Điều này giúp giảm gate size của chip vì ta không cần đồng bộ cho từng nhánh mà chỉ đồng bộ 1 tín hiệu rồi phân nhánh nó sau khi đã đồng bộ.
Trường hợp 4
Phân nhánh data sau FF thứ nhất trong 2 FF. lúc này STA check không thể kiểm tra timing cho path này và sự delay khác nhau của các line này có thể gây ra việc shift data trong output của FF thứ 2.

Hiện tượng trong trường hợp này khá giống như trường hợp 3 bên trên.
Trường hợp 5
Data có thể bị lost nếu như độ rộng của xung data nhỏ hơn 1,5 lần chu kì clock nhận.
Mình nghĩ cái này khá là cơ bản và bạn nào cũng có thể biết. Có nhiều tài liệu nói về vấn đề này. Một số tài liệu ghi là xung data phải lớn hơn 2 lần. Tuy nhiên mình nghĩ 1,5 lần là đủ rồi.
Bạn thử nghĩ nếu xung data quá nhỏ. Lỗi hay gặp là transfer từ clock nhanh sang clock chậm. Data toggle sau khi cạnh clock lên và trước cạnh clock lên tiếp theo của clock C2 thì FF thứ 2 sẽ không capture được. Đây là một lỗi tưởng đơn giản nhưng rất nguy hiểm đấy nhé.
Hãy cẩn trọng với confirmation cho các path như thế này.
Trường hợp 6
Có lẽ đây là trường hợp cuối cùng trong phạm vi hiểu biết của mình về lỗi trong mạch đồng bộ tín hiệu data.

Trong 1 bus nhiều tín hiệu. Chúng ta không được sử dụng mạch đồng bộ cho từng tín hiệu riêng lẽ vì nhu vậy data trong bus sẽ bị thay đổi.
Với một bus chúng ta sẽ có mạch đồng bộ riêng để nhầm tránh sự sai biệt này.
Hôm nay viết dài rồi. Chắc bữa khác mình bổ sung hi vọng nó giúp bạn có cái nhìn tốt hơn về vấn đề đồng bộ mạch async. Nếu có gì sai sót vui lòng gửi comment hoặc gửi mail góp ý cho mình : Trongk10@gmail.com