Tác giả: TrongTran
Ngày: 31/12/2019
Nếu bạn nào đang làm về verification cho system performance (ST) thì bài này sẽ bổ ích cho bạn.
Ngày nay performance quyết định một phần rất quan trọng trong một hệ thống SoC nhắm giúp sản phẩm có thể cạnh tranh trên thị trường.
Việc verification hiện tại không chỉ đơn thuần là kiểm tra function của hệ thống mà còn kiểm tra performance của hệ thống. Nghĩa là một hệ thống chạy đúng là chưa đủ mà phải còn chạy nhanh. Mình lấy ví dụ:
Khi bạn sử dụng 3G và 4G thì đâu là sự khác biệt. Bạn không chỉ quan tâm tới sự ổn định của mạng, ít bị lỗi, bảo mật mà còn quan tâm đến tốc độ mạng.
Vì vậy performance đóng một vai trò cực kì quan trọng trong hệ thống SoC.
Hai yếu tố quan trọng nhất để đánh giá performance của hệ thống đó là Bw (Bandwidth) và latency (Độ trễ).
1. Cách tính BW.
Nhiều tài liệu định nghĩa là BW (bandwidth) là số lượng transaction được transfer trong 1 hệ thống trên một đơn vị thời gian.
Tuy nhiên, Theo mình cái này cần làm rõ lại, Giả sử mình có 1 hệ thống SoC gửi và nhận data với chuẩn AXI protocol.
Mình tiến hành đo đạc và thử nghiệm và dưới đây là kết quả:
Như vậy BW không phụ thuộc vào số lượng transaction kênh AR/AW mà phụ thuộc vào kênh W/R.
BW còn phụ thuộc vào tín hiệu ARSIZE/AWSIZE nghĩa là số lượng byte được transfer trong 1 transaction.
Tóm lại để tính toán được BW chúng ta cần biết các thông tin sau:
B: số byte transfer trong 1 transaction được tính từ ARSIZE/AWSIZE.
T: Run time
N: Số lượng transaction kênh W/R được transfer trong khoảng thời gian “run time”.
Như vậy công thức tính BW sẽ là:
Đơn vị đo lường BW thường là MB/s hoặc GB/s
Ví dụ:
Ngày: 31/12/2019
Nếu bạn nào đang làm về verification cho system performance (ST) thì bài này sẽ bổ ích cho bạn.
Ngày nay performance quyết định một phần rất quan trọng trong một hệ thống SoC nhắm giúp sản phẩm có thể cạnh tranh trên thị trường.
Việc verification hiện tại không chỉ đơn thuần là kiểm tra function của hệ thống mà còn kiểm tra performance của hệ thống. Nghĩa là một hệ thống chạy đúng là chưa đủ mà phải còn chạy nhanh. Mình lấy ví dụ:
Khi bạn sử dụng 3G và 4G thì đâu là sự khác biệt. Bạn không chỉ quan tâm tới sự ổn định của mạng, ít bị lỗi, bảo mật mà còn quan tâm đến tốc độ mạng.
Vì vậy performance đóng một vai trò cực kì quan trọng trong hệ thống SoC.
Hai yếu tố quan trọng nhất để đánh giá performance của hệ thống đó là Bw (Bandwidth) và latency (Độ trễ).
1. Cách tính BW.
Nhiều tài liệu định nghĩa là BW (bandwidth) là số lượng transaction được transfer trong 1 hệ thống trên một đơn vị thời gian.
Tuy nhiên, Theo mình cái này cần làm rõ lại, Giả sử mình có 1 hệ thống SoC gửi và nhận data với chuẩn AXI protocol.
Mình tiến hành đo đạc và thử nghiệm và dưới đây là kết quả:
|
|
(ARLEN)Length
= 16
|
(ARLEN)Length
= 1
|
|
Số
lượng transaction kênh AR
|
690
|
1113
|
|
Số
lượng transaction kênh R
|
16*690
=11040
|
1*1113
= 1113
|
|
BW
|
3532.8
Mb/s
|
356.16
Mb/s
|
|
Thời
gian chạy
|
50
us
|
50
us
|
|
|
(ARLEN)Length
= 16
|
(ARLEN)Length
= 16
|
|
ARSIZE
|
32
bytes
|
16
bytes
|
|
Số
lượng transaction kênh AR
|
690
|
690
|
|
Số
lượng transaction kênh R
|
16*690
=11040
|
16*690
= 11040
|
|
BW
|
3532.8
Mb/s
|
1766.4
Mb/s
|
|
Thời
gian chạy
|
50
us
|
50
us
|
Tóm lại để tính toán được BW chúng ta cần biết các thông tin sau:
B: số byte transfer trong 1 transaction được tính từ ARSIZE/AWSIZE.
T: Run time
N: Số lượng transaction kênh W/R được transfer trong khoảng thời gian “run time”.
Như vậy công thức tính BW sẽ là:
BW = B*N/T
Đơn vị đo lường BW thường là MB/s hoặc GB/s
Ví dụ:
Mình có master A có các thông số sau:
Như vậy ta tính được số transaction kênh R là = 690*16 = 11040 transaction.
Số bit được transfer trong 1 transaction là 4*32 = 128 bit.
Tống số data transfer là 128*11040 = 1413120 bit = 176640 byte = 176.64 KB = 0.17664 MB.
Run time = 50 ns = 0.00005 s.
Vậy BW = 0.17664/0.00005 = 3532.8 MB/s.
Lưu ý:
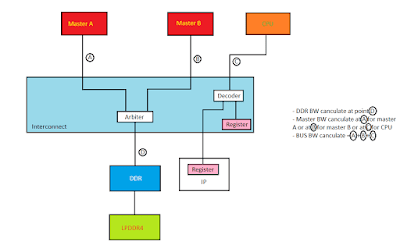
Để đánh giá BW cảu hệ thống chúng ta cần quan tâm đến 3 yếu tố:
2. Cách tính latency.
Chúng ta cần phân biệt các khái niệm sau:
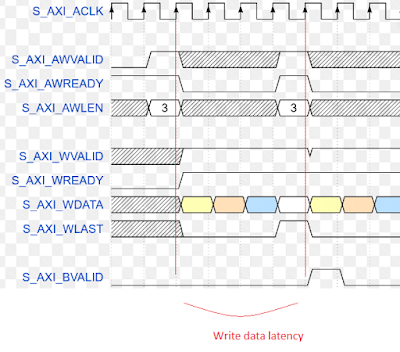
Khoảng thời gian được tính từ sau khi AWVALID & AWREADY = 1 (handshake kênh write address ) cho đến khi WVALID & WREADY & WLAST = 1.
Write latency

Khoảng thời gian được tính từ sau khi AWVALID & AWREADY = 1 (handshake kênh write address ) cho đến khi BVALID & BREADY & BLAST = 1.
Ta luôn có Write latency > Write data latency.
Read latency

Khoảng thời gian được tính từ sau khi ARVALID & ARREADY = 1 (Handshake kênh Read address) cho đến khi RVALID & RREADY & RLAST = 1.
Early response for B channel

BVALID sẽ assert và gửi về slave ngay WVALID & WREADY = 1
Nếu checker đặt tại A thì write latency sẽ nhỏ hơn thực tế
Lưu ý:
Bây giờ xét trường hợp ngược lại. giả sử ta có được số latency trung bình của một transaction. Ta có thể tính được run time cần để transafer một số lượng transaction cụ thể không ?
Xét bài toán bên dưới:
Như vậy thời gian để hệ thống transfer 20 transaction trên là:

T = 5 x 500ns + 7 x ACLK.
ACLK : là chu kì clock.
Nếu chu kì clock là nhỏ so với latency ta có công thức gần đúng là
T = 5*500ns.
- ARSIZE = 4 word (1 word = 32 bit)
- Số lượng transaction kênh AR = 690 transaction
- ARLEN = 16
- Run time = 50 ns
Như vậy ta tính được số transaction kênh R là = 690*16 = 11040 transaction.
Số bit được transfer trong 1 transaction là 4*32 = 128 bit.
Tống số data transfer là 128*11040 = 1413120 bit = 176640 byte = 176.64 KB = 0.17664 MB.
Run time = 50 ns = 0.00005 s.
Vậy BW = 0.17664/0.00005 = 3532.8 MB/s.
Lưu ý:
- Trong tính toàn BW thì 1MB = 1000KB = 1000000 B.
- 1 Byte = 8 bit.
- Gửi transaction với single burst (1 beat) thì BW thấp.
- Gửi transaction với multi burst (> 1 beat) thì BW cao hơn.
- Nguyên nhân là do cùng 1 lượng data nhưng với single burst thì cần gửi nhiều tín hiệu control hơn.
- Cùng số lượng transaction, Data width càng lớn thì BW càng lớn.
- Cùng số lượng transaction, Data width càng nhỏ thì BW càng nhỏ.

Để đánh giá BW cảu hệ thống chúng ta cần quan tâm đến 3 yếu tố:
- BW của master : Được tính tại A (Cho master A) hoặc B (Cho master B) hoặc tại C (Cho master C).
- BW của bus system: bằng tống BW của A + B + C. Lưu ý là BW tối đa của bus system phải lớn hơn tổng các BW của các master gửi tới nó thì hệ thống mới đạ yêu cầu.
- BW của slave (hoặc DDR): Được tính toán tại D.
Chúng ta cần phân biệt các khái niệm sau:
- Write latency
- Write data latency
- Read latency
Write data latency

Khoảng thời gian được tính từ sau khi AWVALID & AWREADY = 1 (handshake kênh write address ) cho đến khi WVALID & WREADY & WLAST = 1.
Write latency

Khoảng thời gian được tính từ sau khi AWVALID & AWREADY = 1 (handshake kênh write address ) cho đến khi BVALID & BREADY & BLAST = 1.
Ta luôn có Write latency > Write data latency.
Read latency

Khoảng thời gian được tính từ sau khi ARVALID & ARREADY = 1 (Handshake kênh Read address) cho đến khi RVALID & RREADY & RLAST = 1.
Early response for B channel

BVALID sẽ assert và gửi về slave ngay WVALID & WREADY = 1
Nếu checker đặt tại A thì write latency sẽ nhỏ hơn thực tế
Lưu ý:
- Gửi transaction với random address thì latency sẽ lớn hơn
- Gửi transaction với sequential address thì latency sẽ nhỏ
- Chú ý tới các fifo trong design nó sẽ ảnh hưởng đến latency trong hệ thống.
Bây giờ xét trường hợp ngược lại. giả sử ta có được số latency trung bình của một transaction. Ta có thể tính được run time cần để transafer một số lượng transaction cụ thể không ?
Xét bài toán bên dưới:
- Latency time của 1 transaction L = 500ns
- ARLEN = 1
- Số transaction cần transfer N = 20 transaction.
- Số OS (Outstanding của bus system) OS = 4.
Như vậy thời gian để hệ thống transfer 20 transaction trên là:

T = 5 x 500ns + 7 x ACLK.
ACLK : là chu kì clock.
Nếu chu kì clock là nhỏ so với latency ta có công thức gần đúng là
T = 5*500ns.